The Future of Enterprise: Big Data
ByThis blog is a follow up to my previous blog on The New Instability and the Future of Enterprise, and was inspired by Daniel Hulme’s General Assembly class on Big Data to Big Wisdom.
There’s a lot of hype at the moment about Big Data, and how it will revolutionize the Enterprise. As a result a lot of software vendors have jumped onto the Big Data bandwagon, re-positioning their products as Big Data to secure a place in the $6.3billion global market, expected to grow to $23.8billion by 2016. The reason for this hype is the technology to analyze and process large data sets is finally becoming commoditised through Open-Source platforms like Hadoop, and Cloud services like Amazon Web Services, that allow customers to quickly and cheaply spin up 100’s or 1000’s of virtual servers to process large data sets.
So what is the hype all about? Big Data is a collection of technologies for storing, analyzing and processing large data sets. It is not really related to the size of the data, for example, your organization doesn’t need to have the PetaBytes of data that a Google or Amazon does to benefit from Big Data technologies (and in fact, that is a rather limited view of your data as you’re probably not considering how you could combine your internal data with all the huge public data sets out there that can drive additional value on your data), its actually more of a discipline on how Enterprises can use data to drive better and faster decisions based on their and related external data.
It’s this distinction that confuses a lot of Enterprises (and Vendors) out there, and its impossible to imagine the future of Enterprise without a clear understanding of the Big Data discipline.
The DIKUW Pyramid
The DIKUW Pyramid is based on the DIKW Pyramid, with an additional step for ‘Understanding’. The Pyramid reflects the functional relationships between how data is used to generate information (data with context), which can be analyzed to generate knowledge, which can be used to make informed, actionable, decisions (wisdom). The DIKUW Pyramid adds ‘Understanding’ to the Pyramid, as Daniel Hulme argues that without understanding the correlations made while analyzing the data (knowledge) Humans risk making false correlations that drive the wrong decisions and results.
Today, the hype and technologies available solve the bottom three levels of the pyramid; the collection of large amounts of data and the processing and analysis of the data to generate insights and knowledge. However, ultimately the pyramid reflects the layers of technology that will belong to the Big Data space over the next 20-30 years, to completely automate decision making across large parts of the Enterprise, creating a real-time, automated, responsive, data-driven Enterprise.
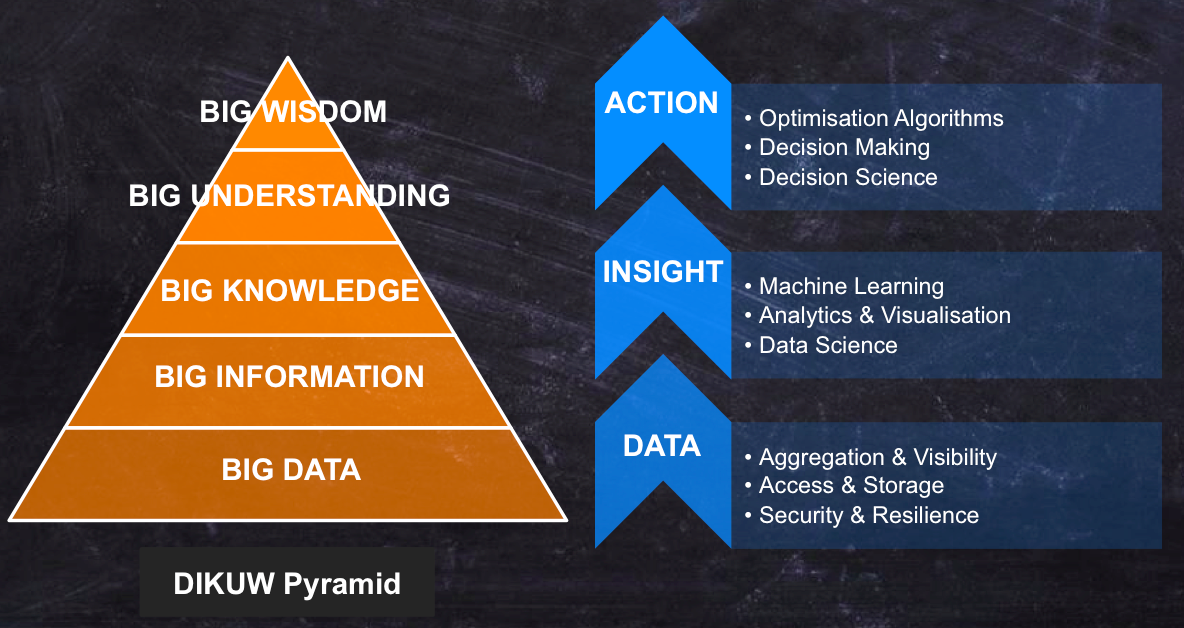
Below is a description of each level in the Pyramid:
- Big Data: This level represents the collection and storage of data. This usually means the databases, file storage systems, and ETL technologies used to collect and store the data where it can be read quickly and efficiently at scale.
- Big Information: This level represents the adding on context to the data to turn it into useful information. For example 1964-04-23 means little by itself, but once metadata is added to it like ‘Date of Birth’ it becomes information related to an entity (person) in the database. Technologies in this level are the same as above,but add additional metadata and context to the data being stored so its more useful for analysis.
- Big Knowledge: This level represents the analysis of the information to draw insights and correlations out of the data that can be used to try and understand and take actions based on the data. This is where most of the focus is today, with data visualization tools like Tableau being used to build dashboards for Enterprises that allow them to view their data, and data scientists being employed by Enterprises to apply Machine Learning algorithms to the data to generate correlations and predictions based on the data sets.
- Big Understanding: This is a new level added by Daniel Hulme. Today this level is done by Data Scientists, who analyze the correlations in the data to try and understand what is the root cause for the change in data. Sometimes correlations can be found in large data sets, that actually aren’t related at all and can lead to bad decisions later on unless we understand the root cause. For example on hot days, ice creams sales increase, but so does the sale of beer. Without any understanding, we could correlate the increase of sales of beer with an increase in ice cream sales, driving our decisions based on beer sales. But with a model of the real world, we can understand that the real correlation is the temperature that day. Many Big Data systems today such as High-Frequency Trading systems (described below) skip this step of trying to understand the correlations in data, resulting in huge shocks to the stock market as ‘dumb’ algorithms react to changes in the data in real time without any understanding of the changes. Today this is because computers do not have a model of the world to understand things like humans do, but some very smart people are trying to solve this problem in the field of Artificial Intelligence.
- Big Wisdom: Very few Enterprises have achieved this level of the pyramid. Once we can analyze and understand the correlations in the data, we can make informed decisions and take actions to respond to changes in the data. For example, using the ice cream example above, if we know the weather forecast several days ahead, we can predict ice cream sales, and automatically order enough ice creams into our stores to meet the predicted demand. In fact this is what supermarkets such as Tesco’s do today. The problem in this area is that humans are inherently bad at making decisions when faced with large amounts of information happening fast in real time. Hence there are new fields in computer science trying to model complex decision making and optimization algorithms to automatically respond to changes in real time with actions that are better and faster than human’s could do themselves.
Once all these levels are combined, you can imagine an extremely fast, responsive, data-driven computer system that takes some of the processes or decisions performed in an Enterprise, making the organization faster and reactive to changes in their market. In fact, in the examples below, you can see that those Enterprises that don’t adopt these technologies, and apply it deeply to the way they run their business, the way many Financial Services and Consumer Web companies have today, will be at a huge disadvantage to their competition, and ultimately fall to the wayside as their competition out-compete them at every turn.
High-Frequency Trading
High-Frequency Trading (HFT) is used by Investment Banks to automate their trading on the stock market at incredibly fast speeds. These systems take in huge amounts of real time data from the stock exchanges, and in order to beat competitors on speed, many banks pay large premiums to host their data centers as close as possible to the stock exchange’s, to shave milliseconds that can allow them to make more money than their competition if they get their trade in first.
In this highly competitive market, computers are the only way banks can analyze, process and action stock exchange data in milliseconds. This means not only do the systems analyze the data, they also have the power to take actions on that data, making trades with real money, based on complex optimization algorithms designed by data scientists working in the banks. However, as mentioned above, the algorithms are ‘dumb’, they don’t understand why the data is changing, they just react to it based on pre-defined algorithms. This is why when new factors affect the market that aren’t foreseen in the complex trading algorithms or data sets, these systems can cause large crashes on the stock market, as they have no understanding of why things are happening.
Automated Price Watching
One of the reasons Amazon is out-competing other retailers, is they are a technology company. As such, they use technology to drive competitive advantage over retailers that don’t have the ability to attract the engineers and scientists to build the types of systems Amazon uses to deliver the right products at the best prices to their customers. As such, many customers who visit retail stores, usually check the price on Amazon, and purchase it from them online instead of the retail store they’re standing in.
However to deliver the best prices, Amazon has to know and react to the prices of competing retailers as quickly as possible. This is a big data problem. They have to monitor millions of products in 1000’s of other retailers worldwide, and automatically drop their prices when they do to ensure they have the best price and can get the customer’s order online instead of them buying it in store. From someone I know who work’s in the industry, they usually see Amazon drop their prices in response to theirs in less than 30 minutes. There’s no way Amazon has people doing this manually, this is an automated Big Data system, the same as the HFT systems described above, that allows Amazon to secure a sale despite competing retailers changing their own prices to compete. As a result, these retailers are really struggling to compete with Amazon as consumers now use their phones to buy it online while standing in the store, resulting in them being the physical showcase for Amazon, and making no money from the sale.
Supermarkets do this every day which is why Sainbury’s can give you a receipt at the end of your shop to show you how much money you saved compared to the other Supermarkets by shopping at their store, and adjust their prices accordingly to compete.
The Data-Driven Enterprises
Hopefully the examples above have made the concepts around Big Data tangible enough to imagine other use cases that can make Enterprises more efficient and competitive. Over the next 20-30 years, as computer systems become more intelligent, you can imagine every Enterprise will change the way they work using data, ultimately using less resources, less employees, and being faster and more responsive than ever before in the market place.
As described in my last blog, many industries are going through a huge transition to a new instability, which means the pace of innovation is accelerating and markets are changing rapidly. In this rapidly and constant changing environment, relying on our instincts on what worked before is dangerous, meaning we need to become more responsive to the data (the facts) around us when making decisions. The facts may point to new directions that contradict our instinct, but need to be taken to stay competitive in the market.
As Enterprises race to automate more of their processes using Big Data like the examples above, at some point it will be impossible for humans to keep up, meaning computers will start taking over many of the real time decisions and replacing humans where possible, so they can react faster to the data that arrives.
Big Data only reinforces some of the trends I mentioned in my last blog, but will ultimately mean:
- Data scientists will become a common role in the Enterprise, with all industries looking to hire data scientists that can help them design algorithms to get insight and take actions on their data. Most likely there will be a shortage of people in this space (I suspect there already is!) meaning that there will be a huge opportunity for vendors and consultancies to supply these skills and tools to help those Enterprises that aren’t sophisticated enough to become a data-driven Enterprise by themselves.
- The best companies will be lead by CEOs and leadership teams that have established a culture of using data, and making decisions based on data, rather than relying on their instincts to drive strategy in their organization.
- Enterprises will need to open up their data to all levels of the organization so that employees on the ground are able to also make day-to-day decisions based on data, rather than replying on head office making decisions on what they should be doing or relying on their own instincts. This will require a huge cultural change in most organizations.
- Enterprises will also need to be more test-driven to get the data they need to make decisions. For example many web companies run A/B split tests on their websites to determine which version of a web page is more effective at converting customers on their site. This methodology will need to be applied to many areas of their business so that Enterprise can “feel” their way through the rapid changes happening in their environment. This will also require the organization to accept failure as a natural part of the learning process as not all tests will give the results expected.
- Enterprises will become smaller, as large parts of their operations are automated by data and algorithms, so they can respond faster to the data. This will mean more smaller Enterprises able to go after smaller niches, and most likely, mass-unemployment as jobs are made redundant in the workplace by computers (more on this later!)
Big Data is ultimately going to require a complete overhaul on the way we run our businesses, the culture in them, and the speed at which they operate. Some Enterprises will be forced by their competition adopting these techniques, as is happening today in retail with online retail companies forcing offline retailers to change or die. But ultimately there will be losers as change of this magnitude will be hard for most organizations, and the start-ups of today who are adopting many of these principles from day one, will become the leaders of tomorrow in their respective markets.
In a future blog I will dive into Machine Learning, a branch of Artificial Intelligence, that will become a key part of the data driven Enterprise as Big Data becomes prevalent. Please follow this blog or my Twitter feed to get notified when its up.

Reblogged this on Sutoprise Avenue, A SutoCom Source.
[…] morning David Gildeh alerted me to the existence of the DIKW pyramid that you see above. It’s been around for […]
[…] morning David Gildeh alerted me to the existence of the DIKW pyramid that you see above. It’s been around for […]
[…] The Future of Enterprise: Big Data | David Gildeh […]
[…] last blog talked about the effect of Big Data on the future of Enterprise. When it comes to generating […]